正则在编程中一般处处可见,这次终于花了时间把它的语法,基本规则都弄清楚明白了。利用视频加教程的方式,理解起来还是挺好的(参考博客:http://deerchao.net/tutorials/regex/regex.htm),剩下的就是在平时的利用中去具体实践找坑咯。
一、符号说明
1. ^ ,匹配目标字符串开始的位置,表示一个锚,告诉正则匹配开始匹配的位置。如果放在字符集中,如 [^a-z] 表示除a到z的任意字符,表示取反。如 [^3] ,表示不是3的任意字符。
2. $ ,匹配目标字符串结束的位置,同样表示一个锚。比如在表单验证用户输入的名字是否全为中文时可以在前端js中这样匹配 ^[\u4e00-\u9fa5]$ ,这里的^&分别在首位表示从字符串的开始匹配到结束。同样用于定位的还有 \b 与 \B 。
3. ? ,匹配前面的子表达式0次或1次,如 reader? 可以匹配 reader和reade ,它起作用的是子表达式,这里的 ? 就是表示匹配 r 1次或者0次。另外:? 可以表示懒惰模式,正则匹配的时候默认的是贪婪模式,即尽可能的匹配多的字符串。如 o+ ,可以匹配foooood里的全部o,如果换成 o+? 则只会匹配一个o,因为+表示匹配至少一次,因此在用?修正后当它匹配到f后的第一个o即结束匹配。
4. + ,匹配前面的子表达式1次或多次。
5. * ,匹配前面的子表达式0次或多次。
6. {num},匹配前面的子表达式num次,这里表示一个确定的匹配次数。如 a{5} ,表示匹配a5次。
7. {num,},匹配前面的子表达式至少num次。
8. {minNum,maxNum},匹配前面的子表达式最少minNum次,最多maxNum次。逗号之间不能有空格。以上就是匹配的限定次数,同样可以用?来修正为懒惰模式。
9. .,元字符,表示除换行符外的任意字符。
10. \w,表示字母数字和下划线。等价于 [a-zA-Z_] 。相反的即为 \W 。
11. \s,表示任意空白符。等价于 [] 。相反的即为 \S 。
12. \d,表示数字。等价于 [^\d] 。相反的即为 \D
13. \f,表示换页符。
14. \n,换行符。
15. \r,回车符。
16. \t,制表符。
17. \v,垂直制表符。
18. \num,num是一个正整数,表示一个后向引用。如 (\d)\1,当使用 () 指定一个子表达式后,该子表达式捕获的内容将自动分配一个组号,默认从1开始,规则是从左向右,从左括号为标志,第一个出现分组的为1,第二个为2,依次类推。当然你可以自己主动命名。如 (?<group1>a) ,如果要反向引用group1分组捕获的内容,则用 \k<group1> 。同样如果你想让该分组不计入命名,则可以这样写 (?:\d)。如下图一个反向引用的例子:
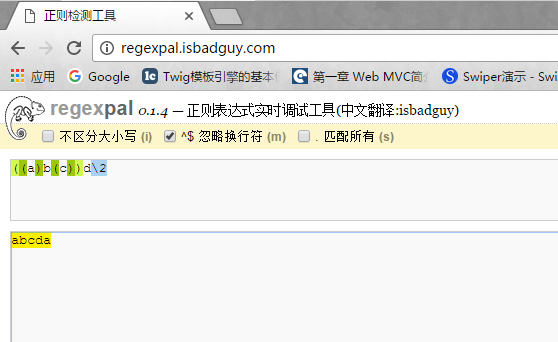
这里的\2则引用的是(a)匹配的内容。
19. \un,u表示unicode编码。其中 n 是一个用四个十六进制数字表示的 Unicode 字符。如js里可以用 [\u4e00-\u9fa5] 来匹配汉字。
二、正则匹配规则
1.字符转义。假如正则匹配要匹配那些特殊字符(正则表达式中的语法字符),如 (,\,此时可以用 \ 来转义,表示匹配该特殊字符。 比如 \\匹配 \ 。 \( 匹配 (。
2.分支条件。举一个例子,如果我想匹配下面字符串 Duang~duang ,我们发现前后就是D和d的区别。此时用到分支条件 | 表示D或者d,如下图:
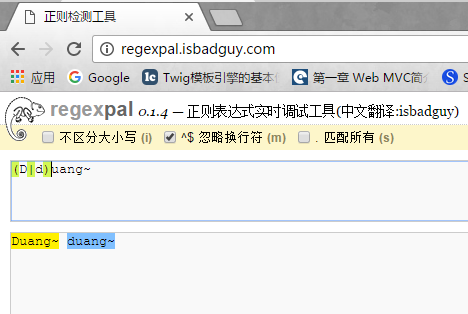
值得一提的是,| 分支条件判断的是左边部分和右边部分,而不是子表达式。如下图:
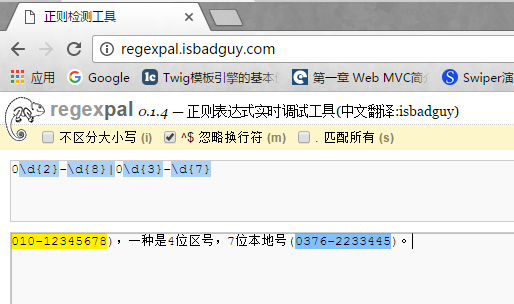
这里|左右分别都纳入规则。
3.零宽断言。零宽断言对于我的理解就是规定匹配前导后导。比如我想匹配这样的<p>name</p><p>sex</p>中的name与sex,即标签中的内容。我们可以拟定规则为匹配前缀为<p>后缀为</p>中间的内容。这里就可以用到零宽断言。不过就目前接触的来看,有时对于具体的语言支持的还是不怎么好。
3.1零宽度正预测先行断言。(?=exp) ,即后缀符合exp的。如我想查找以er结尾的单词。

可以看出我们匹配出来的只有er前面的部分,所以零宽的意思就在这里,匹配的规则它不在匹配的内容里。
3.2零宽度正回顾后发断言。(?<=exp),即前缀符合exp的。在php里面,零宽度正回顾后发断言里的匹配规则不支持+,*,?这样的匹配规则,它需要有明确的匹配次数。而js直接是不支持此方式。
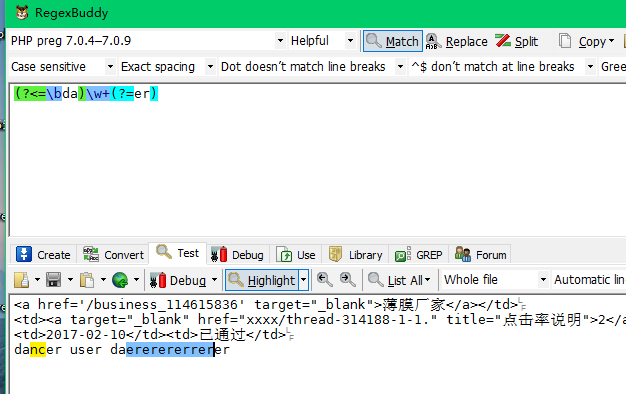
3.3零宽度负预测先行断言。(?!exp),即后缀不是exp的。这里与零宽度正预测先行断言即是相反的意思,我们可以从语法上看出即=替换为!符号,表示取反。
3.4零宽度负回顾后发断言。 (?<!exp),即前缀不是exp的。想想如何匹配结尾不是er的单词。
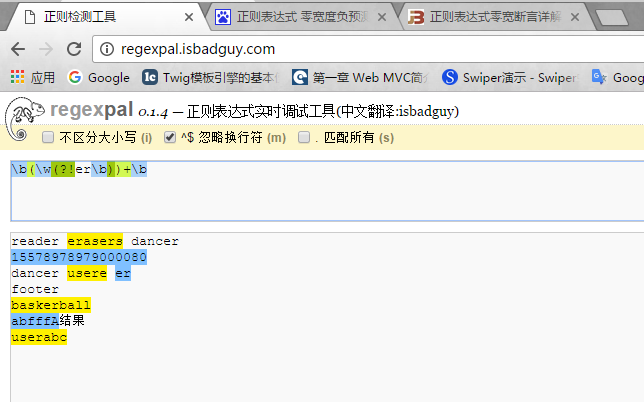
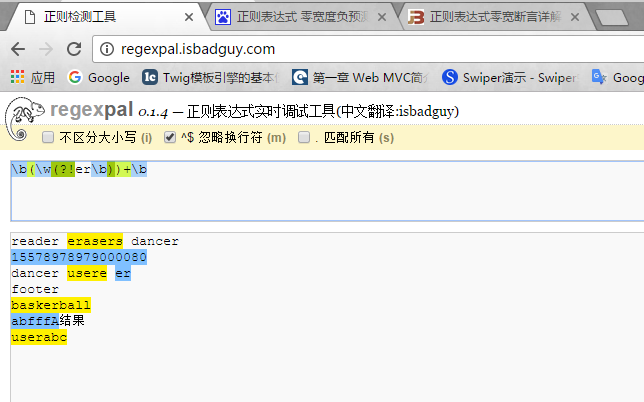
\b((?!er\b)\w)+\b 。首先是(?!er\b)表示结尾不是er,然后加上\w。
三、正则匹配选项
在正则匹配中,我们可以设置匹配的方式,比如忽略大小写,忽略换行,忽略表达式中的非转义空白。在php中常用的有这几个,i,表示忽略大小写;s表示将匹配规则中的.更改为匹配包含换行符的所有字符;m表示为忽略换行符,默认情况下,正则表达式匹配是从字符串的开始到结束,目标字符串一般包含很多行,当启用了这个修饰符之后,则匹配的位置则从每行(即目标字符串中任意换行符之前或之后,当然另外, 还分别匹配目标字符串的最开始和最末尾位置);U修改为非懒惰模式;u,模式字符串被认为是utf-8的,暂时用到的在匹配中文时/[\x{4e00}-\x{9fa5}]/u。
四、上述未提到的
1.递归