
最近业务上需要拿到很多车型数据,无奈只能去各大网站爬取了。去Github上搜了搜,比较突出的似乎就PHPspider,于是就选它了。经过几个站点的数据爬取,的确挺好用。下面记录一下几个实际的例子。
案例一:从网站http://www.17vin.com/brand.html拿到已收录的所有品牌车系下的车型数据:需要的字段把包括有,品牌、车系、年款、发动机型号、排量、变速箱档位等。整个的网站结构为:
- 品牌页:http://www.17vin.com/brand.html
- 车系页:http://www.17vin.com/series.html?p=YnJhbmQ95L-d5pe25o23
- 车辆页:http://www.17vin.com/models.html?p=YnJhbmQ95L-d5pe25o23JmNoYW5namlhPeS_neaXtuaNtyZzZXJpZXM9OTEx
所以整体的思路即从各个品牌出发,拿到所有的车系,然后最终拿到所有的车辆数据。
OK,这里我们穿插一下,回过头来,看看PHPspider的爬虫的基础介绍。文档在这里:https://doc.phpspider.org/。先了解一下它的核心配置有哪些项目,比如config详解里面提到的各种页面级别的URL设置,基础的数据库设置等。可以从github上下载的代码里,找到demo可以先看一下,了解一个基本的结构。
特别关键的,一定要看下文档中介绍的回调函数章节提到的系统处理顺序:https://doc.phpspider.org/callback.html。
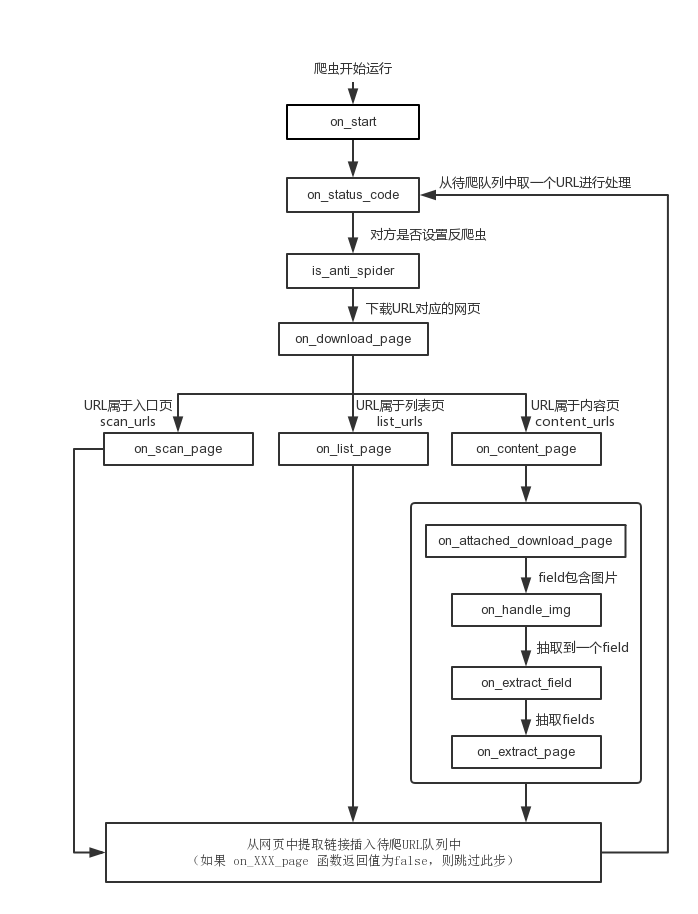
这里图中提到的,在下载对应的URL的页面后,有三个地址分支:on_scan_page、on_list_page、on_content_page,它这里会自动根据你的congfig配置的URL去识别判断当前是属于哪一种页面,然后就调用哪一个回调函数。了解到这一点,我们的抓取工作流程就简单明了了。
所以,针对案例一,抓取如下:
<?php
require_once __DIR__ . '/../autoloader.php';
use phpspider\core\db;
use phpspider\core\phpspider;
use phpspider\core\selector;
//下面这段话(“Do NOT delete this comment”)是PHPspider作者框架硬性要求的,如果不加这个运行会报错,我看了下源码,这段话做了字符串匹配,检测是否存在。。。(我也不知道这句话有啥意义?,刚开始把这句话删了倒腾了半天)
/* Do NOT delete this comment */
/* 不要删除这段注释 */
$configs = [
'name' => '17vin',
'log_show' => true,
'log_file' => __DIR__ . '/../data/log/info.log',
'log_type' => 'info',
'tasknum' => 1,
//进程数
'save_running_state' => true,
//保存抓取进度,这里如果是测试的时候,我一般填false,保证每次可以重头抓取;如果是正式运行,则改为true,保证抓取的进度。它是根据url的唯一性放入到redis做校验的
'domains' => array(
'www.17vin.com',
//域名
),
'scan_urls' => array(
'http://www.17vin.com/brand.html'
//主页地址,即品牌页
),
'list_url_regexes' => array(
"http://www.17vin.com/series.html\?p=\w+"
//车系页,需要保证能被适配,所以这里后面参数用了正则
),
'content_url_regexes' => array(
"http://www.17vin.com/models.html\?p=\w+"
//具体车辆页
),
'max_try' => 3,
'export' => array(
'type' => 'db',
'table' => '17vin',
),
'db_config' => array(
'host' => '192.168.240.1',
'port' => 3306,
'user' => 'root',
'pass' => '123',
'name' => 'spider',
),
'queue_config' => array(
'host' => '192.168.240.3',
'port' => 6379,
'pass' => '',
'db' => 3,
'prefix' => 'phpspider',
'timeout' => 30,
),
'fields' => array(
//抓取的所有字段,匹配规则,重复方式等
array(
'name' => "brand",
'selector' => "//table[contains(@id,'tableSort1')]//tr[position()>1]/td[1]/text()",
'required' => true,
'repeated' => true,
),
array(
'name' => "series",
'selector' => "//div[contains(@class,'car-series-attached')]/text()",
'required' => true,
'repeated' => false,
),
array(
'name' => "year",
'selector' => "//table[contains(@id,'tableSort1')]//tr[position()>1]/td[2]/text()",
'required' => true,
'repeated' => true,
),
array(
'name' => "model",
'selector' => "//table[contains(@id,'tableSort1')]//tr[position()>1]/td[3]/text()",
'required' => true,
'repeated' => true,
),
array(
'name' => "engine",
'selector' => "//table[contains(@id,'tableSort1')]//tr[position()>1]/td[4]/text()",
'required' => false,
'repeated' => true,
),
array(
'name' => "displacemen",
'selector' => "//table[contains(@id,'tableSort1')]//tr[position()>1]/td[5]/text()",
'required' => false,
'repeated' => true,
),
array(
'name' => "gear",
'selector' => "//table[contains(@id,'tableSort1')]//tr[position()>1]/td[9]/text()",
'required' => false,
'repeated' => true,
),
),
];
$spider = new phpspider($configs);
/**
* 主页根据品牌获取下一级目录:车系
*
* @param $page
* @param $content
* @param $phpspider
* @return bool
*/
$spider->on_scan_page = static function($page, $content, $phpspider) {
//通过xpath的提取方式,拿到所有的品牌,然后添加url进行下一步的爬取
$listUrl = selector::select($content, "//div[contains(@class,'abc_box_right')]/ul/li/a/@href");
foreach ($listUrl as $item) {
//下一级list地址 http://www.17vin.com/series.html?p=YnJhbmQ9QVJDRk9Y
$url = 'http://www.17vin.com' . $item;
$phpspider->add_url($url);
}
// 将主页的所有地址推送出去后,就返回false,告知结束,通知爬虫不再从当前网页中发现待爬url
return false;
};
/**
* 车系列表,将当前车系attach到内容页,同时添加内容页爬取
*
* @param $page
* @param $content
* @param $phpspider
* @return bool
*/
$spider->on_list_page = static function($page, $content, $phpspider) {
$href = selector::select($content, "div.step_box_body2 div.series_box_loop ul li", 'css');
if ($href) {
if (is_string($href)) {
//详情页地址
$url = 'http://www.17vin.com' . selector::select($href, '//a//@href');
$series = selector::select($href, '//a/text()');
//attach html
,因为车辆详情页没有车系的数据,所以只能将当前的车系内容html放到车辆详情页,方便一同抓取,这里采用add_url的参数:context_data,它可以将内容附加到到目标地址的网页内容中去
$seriesHtml = '<div class="car-series-attached">' . $series . '</div>';
$phpspider->add_url($url, [
'method' => 'get',
'context_data' => $seriesHtml,
]);
} elseif (is_array($href)) {
foreach ($href as $item) {
//详情页地址
$url = 'http://www.17vin.com' . selector::select($item, '//a//@href');
//attach html
$series = selector::select($item, '//a/text()');
$seriesHtml = '<div class="car-series-attached">' . $series . '</div>';
$phpspider->add_url($url, [
'method' => 'get',
'context_data' => $seriesHtml,
]);
}
}
}
// 通知爬虫不再从当前网页中发现待爬url
return false;
};
//最终结果页,不需要进一步的链接获取,所以直接返回false
$spider->on_content_page = static function($page, $content, $phpspider) {
// 通知爬虫不再从当前网页中发现待爬url
return false;
};
/**
* 处理最终抽取的数据
,根据实际抓取的数据进行判断处理
*
* @param $page
* @param $data
* @return bool
*/
$spider->on_extract_page = function($page, $data){
if (is_string($data['brand'])) {
//$data['brand']是字符串,则说明data是一条单一完整数据
db::insert('17vin', $data);
} elseif (is_array($data['brand'])) {
//否则,拆分成二维数据批量插入
$rows = count($data['brand']);
$insertData = [];
for ($i = 0; $i < $rows; $i++) {
$insertData[] = [
'brand' => $data['brand'][$i],
'series' => $data['series'],
'year' => $data['year'][$i],
'model' => $data['model'][$i],
'engine' => $data['engine'][$i] ?? '',
'displacemen' => $data['displacemen'][$i] ?? '',
'intake_form' => $data['intake_form'][$i] ?? '',
'fuel_type' => $data['fuel_type'][$i] ?? '',
'gearbox' => $data['gearbox'][$i] ?? '',
'gear' => $data['gear'][$i] ?? '',
];
}
//保存到数据库
db::insert_batch('17vin', $insertData);
}
return false;
};
$spider->start();
在控制台启动,很快就抓取完成:
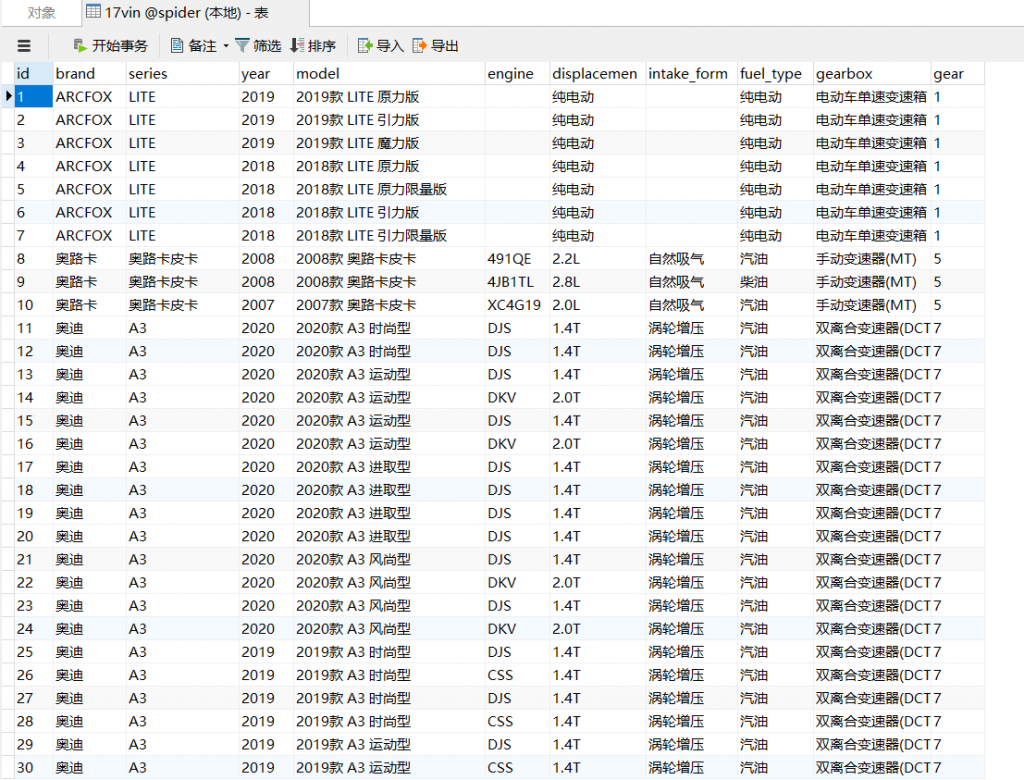
爬取数据结果
再度重复一遍,上面的整个流程,比较特殊的地方是,中间页的数据,也就是车系页,它的数据是在车型页没有显示的,所以只能在车系页的时候,将当前车系一同带到下一级去,所以用到了PHPspider提供的方法,通过add_url的参数去配置,这里作者提到的文档见:如何爬取列表页中的数据?
案例二:抓取懂车帝的所有车辆数据。通过页面规则,最终发现懂车帝的数据是直接通过api请求的,同时,它的车辆接口数据,是通过自增的车辆id来取请求的,如:https://www.dongchedi.com/motor/car_page/v4/get_entity_json/?car_id_list=1000&version_code=444,这里的car_id_list的即为车辆的id,最终尝试出了id的最大值,于是直接就开始爬取了。
关键点1:因为对方是直接接口,所以就不涉及到各种层级页面去获取了。同时这里指出PHPspider的一个文档错误:config配置里面的filed抓取方式selector_type提到了支持 jsonpath,实际是不支持的。所以这里得注意一下。
关键点2:这里需要用到代理,第一次我直接去爬取的时候,发现在拿到了接近数据1000的时候,请求就失效了,通过页面去请求,发现页面返回的数据是空的,然后换了wifi,又好了。所以这里IP被屏蔽了。因此需要用到大量的代理IP去处理,而我看了下文档,它那里虽然支持了代理地址,但是都是固定的,所以这一块的处理,我直接简单粗暴的调整了下requests.php的源码:
if (self::$proxies)
{
//这里接入redis,保存上一次获取的有效的代理IP
$proxy_key = 'proxy_ip';
cls_redis::set_connect('current', array(
'host' => '192.168.240.3',
'port' => 6379,
'pass' => '',
'db' => 3,
'prefix' => 'phpspider',
'timeout' => 30,
));
$cache = cls_redis::get($proxy_key);
if ($cache) {
$proxy = $cache;
}
try {
$proxyIp = file_get_contents('http://kuyukuyu.com/api/projects/get?uuid=****');
if ($proxyIp) {
$proxy = 'http://' . $proxyIp;
cls_redis::set($key, $proxy, 60);
} else {
echo PHP_EOL . '未获取到代理地址' . PHP_EOL;
return false;
}
} catch (\Throwable $t) {
echo PHP_EOL . '获取代理超时' . PHP_EOL;
return false;
}
if (isset($proxy) && $proxy) {
curl_setopt( self::$ch, CURLOPT_PROXY, $proxy );
}
// $key = rand(0, count(self::$proxies) - 1);
// $proxy = self::$proxies[$key];
}
****省略
//如果此次请求不成功,则删除原来保存的代理地址
if ((self::$status_code !== 200) && isset($proxy_key)) {
cls_redis::del($proxy_key);
}
这里用到的代理,之前找了好几家,免费的基本都用不了,最后在v2ex上看见有人推荐了酷鱼,于是试用了一下,挺靠谱的,请求方式也挺合理。上一个推销链接自取(有优惠):https://kuyukuyu.com?u=5344
最终,加了上面代理之后,我以1个tasknum,间隔10ms的速度,拿到了所有车型数据:
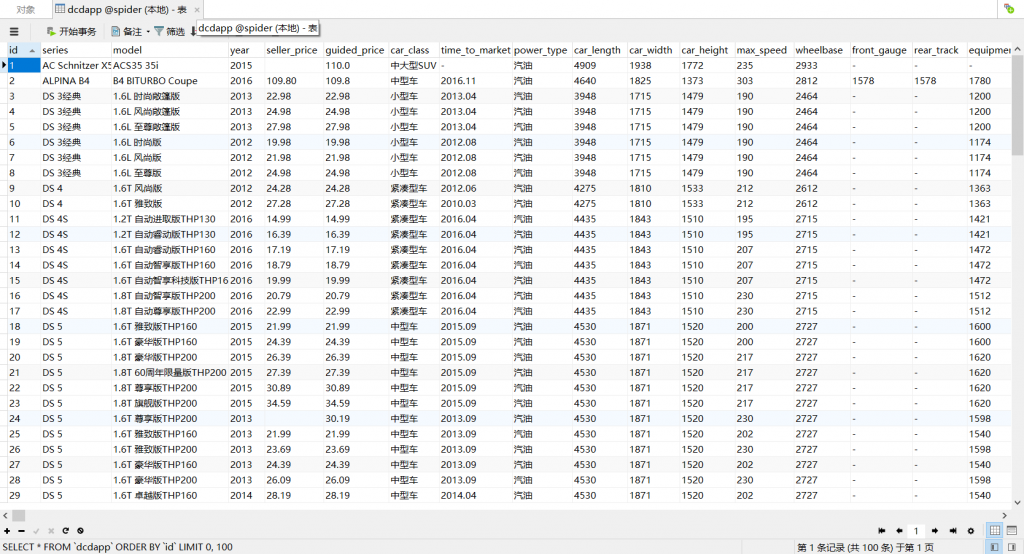
随后,又爬取了所有懂车帝的车系,品牌数据。说实话,懂车帝的车辆图做的真不错

综上,通过此次偶然的机会,有幸认识到PHPspider,的确一个高效的爬虫利器。当然还有其他的特性没有使用到,比如针对如果某些网站需要登录的或者其他防爬措施的,利用该系统该如何解决,以后有机会,继续补充一下