
前天3月29号,刚准备吃饭,手机上收到了系统上一个Error Alert提示,打开进去看原来是出现一次重试超时,后面是正常的。然后无意跳去看一下所有服务总览页面,发现另一个服务有几个error,于是进入详情,发现一直提示“验证码637592发送失败,data not accepted”。
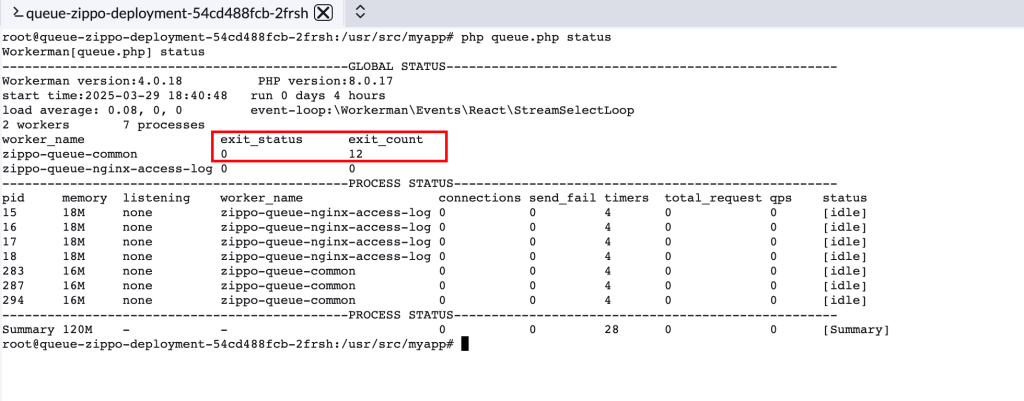
以上报错来自一个邮件推送服务,利用webman+rabbitmq(采用的workerman/rabbitmq)做的异步消费。这就很奇怪了,在程序设计方面,所有的环节都有做catch处理,最终都是返回ack。不应该会出现同一条邮件重复发送,紧接着又看了一下具体的系统日志,发现发送邮件的整体都是正常输出的,只是邮件发送的结果是data not accepted,最终都是会返回ack,同时还有进程退出启动的日志。更诡异的是,仅仅只有进程退出和启动的我们自己log的信息,并没有出现workerman调度进程输出的日志(在workerman下,假设进程出现异常或者自己exit了,主进程会监听到并输出具体的退出错误日志),同时利用workerman的status命令,查到exist_count为12,但是exist_status为0,太奇怪了。
线上问题先处理:我们具体排查发现推送邮件给SMTP服务时,一直是失败的(给我们内部发邮件都是失败的),所以联系运维同学帮排查,的确是SMTP服务出问题了(它发给收件人之后,但是请求另一个组件时耗时很久,直到对方返回504时,它才把结果返回给我们),于是在运维修正之后,我们这边再推邮件就正常了,也没有重复消费的问题。
思来想去,不得其解,于是当晚把上述的过程跟workerman作者描述了一下,很快第二天早上他回邮件了,最后他指引出:如果没有出现workerman进程调度日志,并且exit_status是0,那说明是有调用到Worker::stopAll()导致的,而workerman/rabbitmq的库,它在disconnect时,会调用到该方法。于是自己测试了一下主动stopAll方法,的确会出现线上的场景。但是我们自己并不会主动的disconnect,那它是在哪里被调度的呢?
再次看disconnect方法,它继承的是bunny/Client的,仔细看了一下,调用链路如下:在select loop下,会触发read,当stream是eof时,则主动disconnect,进而导致Worker::stopAll()。
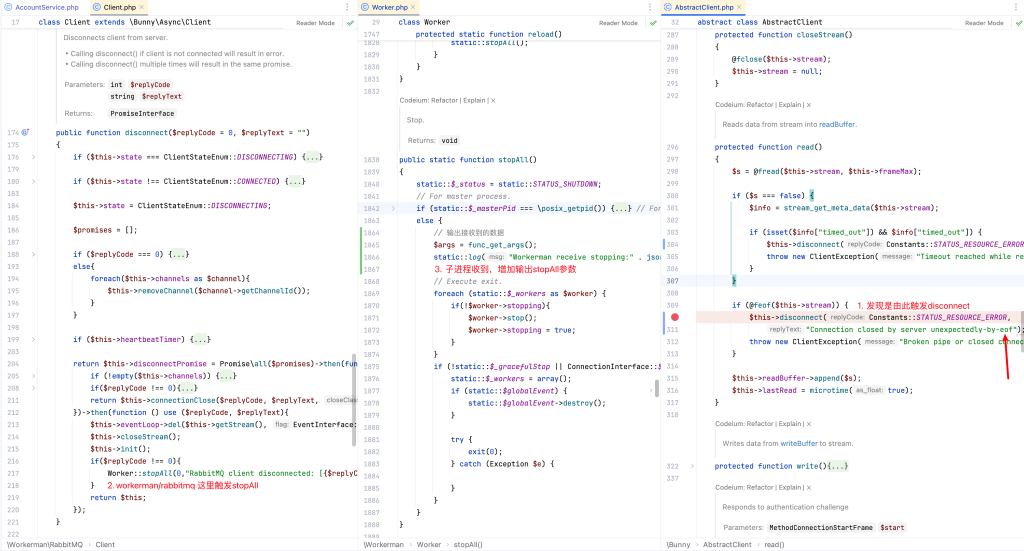
那么问题来了,为什么stream是eof?另外我发现workerman/rabbitmq实现心跳时,假设它失败也会调用stopAll,联想到当时线上发送邮件时,耗时了非常久,并且我偶然间通过本地x-debug断点调试时,也会出现这个问题。那是不是跟心跳有关系?也就是在heartbeat到期后,因为进程还一直在被阻塞,它根本无法响应,所以出现异常了?所以再次做了一次测试,本地将业务逻辑直接sleep 120s,heartbeat设置为30s,测试果真和线上故障时所有细节一致。然后又反验证一次,把业务逻辑设置为sleep 30s,heartbeat设置为60s,系统运行正常,没有重复消费的问题,消息有正常被消费。这下,可以明确知道是这个原因引起的了。
但是回到根本,为什么heartbeat没有被执行,它的stream就是eof了?有一些知识盲区了,根据AI,我关联了几个重要文件,并阐述了过程,它给到了一个这样的结果:
Let me explain the process of how a heartbeat timeout can lead to a stream being EOF (End Of File).
Heartbeat Timeout
When a client connects to a RabbitMQ server, it establishes a connection and starts sending heartbeats to the server at regular intervals (defined by the
heartbeatparameter). The server expects to receive these heartbeats within a certain time window (defined by theheartbeat_timeoutparameter). If the server doesn’t receive a heartbeat within this time window, it assumes the client is no longer connected and closes the connection.Stream EOF
When the server closes the connection due to a heartbeat timeout, it sends a TCP FIN packet to the client, indicating the end of the connection. The client, in turn, receives this FIN packet and marks the stream as EOF.
Here’s a step-by-step illustration of the process:
- Client sends a heartbeat to the server (e.g., every 30 seconds).
- Server receives the heartbeat and resets its internal timer.
- If the client doesn’t send another heartbeat within the
heartbeat_timeoutwindow (e.g., 60 seconds), the server assumes the client is no longer connected.- Server sends a TCP FIN packet to the client, indicating the end of the connection.
- Client receives the FIN packet and marks the stream as EOF.
- When the client tries to read from the stream (e.g., using
feof($this->stream)), it returnstrue, indicating the end of the file (EOF).In your case, when the business logic takes longer than the
heartbeat_timeoutwindow (60 seconds), the server closes the connection due to a heartbeat timeout, leading to the stream being marked as EOF.By increasing the
heartbeat_timeoutvalue or implementing a mechanism to send heartbeats periodically, you can prevent the server from closing the connection and avoid the stream being marked as EOF.
根据它的描述,我又再一次看了下rabbitmq的文档,里面的确提到了这个机制(其实我之前一直以为workerman/rabbitmq设置的heartbeat是一个普通的Timer):https://www.rabbitmq.com/docs/heartbeats#heartbeats-interval 当heartbeat连续两次失效后,该端会认为对方已经不可达,然后就会关闭链接。
这样一来就完全解释得通了,并且后面联系运维拿到了当时rabbitmq的日志,和文档描述一致,有心跳丢失导致连接断开的日志:
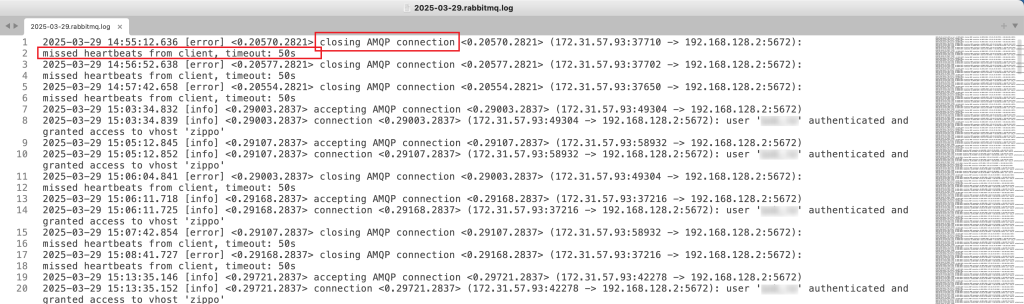
以上就是整个过程,问题产生是有好几个因素诱发,最终得一层一层去剥开,并且也发现了一些不足需要去弥补。
在这里还是得感谢walkor的指出,不然真找不出头绪!